
Diving Deeper: Refining System Design Through Key Components
Building the Blueprint: Mastering the Art of System Design Refinement

System design interviews require more than just a surface-level understanding of concepts. They demand a deep dive into the nuances of requirements, entities, APIs, high-level designs, and focused problem-solving. This post will build upon the foundation laid in the beginner’s guide and provide actionable strategies for tackling these critical aspects.
By the end of this post, you’ll have a clear roadmap for identifying functional and non-functional requirements, defining core entities, outlining APIs, creating high-level designs, and diving deep into system bottlenecks.
1. Functional and Non-Functional Requirements
What Are Requirements?
Requirements form the foundation of any system design process. They define what the system is expected to do (functional) and how well it should perform (non-functional). Properly identifying requirements ensures clarity and alignment with the problem’s scope.
A Structured Approach to Identifying Functional Requirements
Start with the User
For user-facing applications, identify the core requirement in terms of user actions.
Example: For a ride-hailing app, users need to book a ride, track the driver, and make a payment.
Ask Targeted Questions to yourself
To uncover read and write requirements, ask the following questions to yourself. These help identify the core read and write requirements.
Who is providing the data?
Example: A rider provides their pickup and drop-off locations.
Who is consuming the data?
Example: Drivers need to access the rider’s location to accept a ride request.
To identify additional user actions impacting the core requirements, ask:
What actions could modify or depend on this data?
Example: Updating the ride status from pending to completed.
Cancelling a ride before a driver accepts it.
Categorize Requirements
Group them into must-have, nice-to-have, and optional to prioritize effectively. Do not commit to a big list of requirements as your interview has a time limitation. For a typical 35 to 40 minutes interview, commit to not more than 3 or 4 functional requirements. If you have a big list, tag the requirements by priority (by grouping them into P0, P1, P2 etc).
A Structured Approach to Identifying Non-Functional Requirements
Non-functional requirements (NFRs) define the system's operational attributes. Address these using the following structure:
Focus on Core System Properties
Use the CAP Theorem to assess:
Consistency: Should all users see the same data at all times?
Availability: Should the system respond even if some components fail?
Partition Tolerance: Can the system handle network splits?
Consider trade-offs based on the system’s use case:
For a payment system, prioritize consistency over availability.
For social media feeds, prioritize availability with eventual consistency.
Analyze Latency and Performance
Identify latency requirements for read and write operations.
Example: For a ride-hailing app, location updates must be near real-time for driver and rider tracking.
Evaluate Scalability
Think about how the system will handle increasing loads.
Example: Will adding more users or data impact response times?
Understand Read vs. Write Characteristics
Determine whether the system is read-heavy or write-heavy.
Example:
A content delivery system (like Netflix) is read-heavy.
A logging service is write-heavy.
Incorporate Reliability and Fault Tolerance
Ensure the system can gracefully recover from failures.
2. Core Entities
Identifying core entities is about translating system requirements into tangible building blocks.
How to Identify Core Entities
Start with the User Journey:
Map out the end-to-end user flow and identify touchpoints.
Example: For a ride-hailing app, entities could include Users, Rides, and Drivers.
Look for Nouns in Requirements:
Requirements often describe entities indirectly. For example:
"Drivers should be able to accept ride requests" → Entity: Driver.
"Trips must have a start and end location" → Entity: Trip.
Differentiate Between Entities and Attributes:
Avoid treating attributes as entities. For example, "Location" in a ride-hailing app is an attribute of "Trip" or "Driver.".
Establish Relationships Early:
Define how entities interact.
Example: A Driver is assigned to a Trip, and a User books a Trip.
3. APIs
Why Are APIs Critical?
APIs define how users and components interact with your system. Well-designed APIs ensure clarity, efficiency, and extensibility along with seamless communication and functionality.
Best Practices for Designing APIs
Adopt REST or GraphQL:
REST works well for hierarchical data; GraphQL shines when clients need specific data.
Define Clear Inputs and Outputs
Use JSON or similar formats to specify parameters and responses.
Example:
POST /ride/create
Input:{ "pickup": "A", "dropoff": "B" }
Output:{ "ride_id": 12345 }
Follow CRUD Principles:
Clearly define Create, Read, Update, and Delete operations for each entity, if applicable.
Example: For a Ride entity:
POST /rides → Create a new ride.
GET /rides/{id} → Retrieve ride details.
PUT /rides/{id} → Update ride information.
DELETE /rides/{id} → Cancel a ride.
Ensure Idempotency:
Repeatable API calls (e.g., retries) should yield consistent results.
Prioritize Security:
Use authentication (e.g., OAuth2) and validation to safeguard APIs.
Optimize for Performance
Combine APIs where appropriate to reduce roundtrips.
Example: Use a batch API to retrieve multiple resources.
Versioning
Use versioning to avoid breaking changes.
Example:
/v1/ride/create.
4. High-Level Design
What Is High-Level Design?
High-level design (HLD) is the process of outlining the major components, their interactions, and the overall system architecture without diving into the intricate details. Think of it as creating the blueprint of your system that gives a bird’s-eye view of how the system works.
Purpose of High-Level Design
Foundation for Detailed Design: It provides the groundwork to drill down into specifics later.
Focus on Broad Problem Areas: Helps you identify potential bottlenecks, trade-offs, and areas for optimization.
Ensures Alignment: Establishes a common understanding between stakeholders (e.g., interviewers, team members).
The Analogy: High-Level Design Is Like a Brute-Force Solution
If you come from a coding background, think of high-level design as a brute-force solution to a coding problem:
Goal First, Optimizations Later
When solving a coding problem, your first step is to identify a solution that works, even if it's not optimal. Similarly, in system design, the high-level design ensures your system meets the core requirements, leaving optimizations for the detailed design phase.
Big Picture, Not Details
A brute-force coding solution doesn't worry about edge cases or performance initially—it focuses on solving the problem at hand. High-level design works the same way, concentrating on components, interactions, and flow without getting bogged down by low-level details like database schemas or API response formats.
Iterative Refinement
Just as you iterate on a brute-force solution to create an optimized one, you refine the high-level design into a more detailed and efficient low-level design by addressing scalability, reliability, and performance.
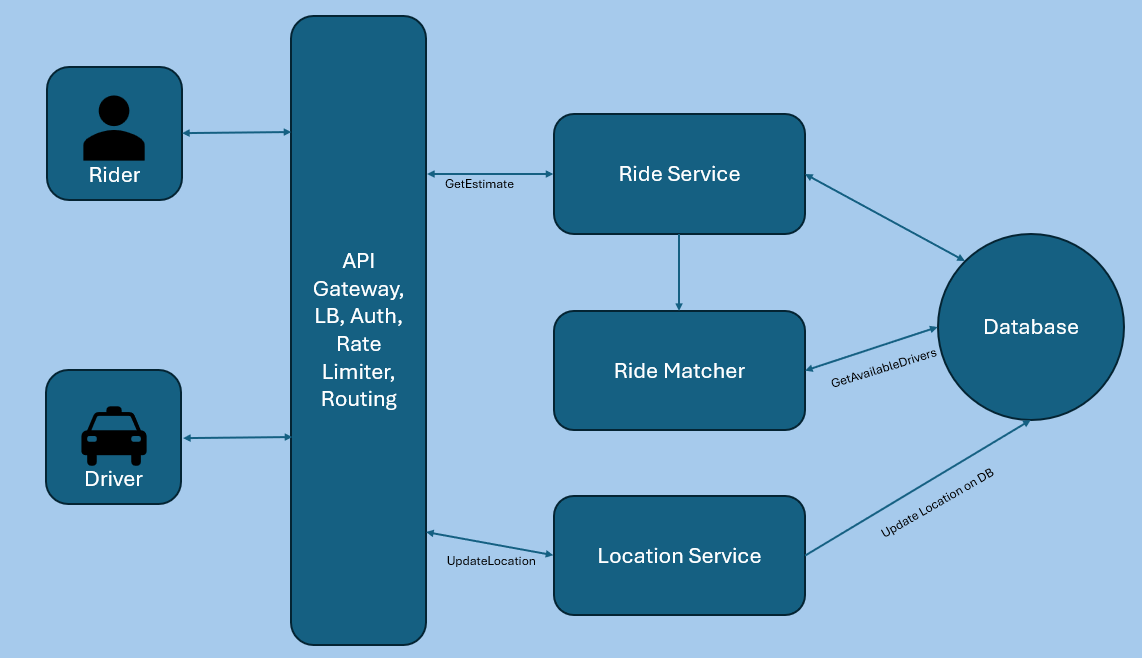
Example: Building a Ride-Hailing App
For the high-level design:
Identify core components: Rider App, Driver App, Backend System, Notification Service.
Define interactions:
Rider App sends ride requests.
Backend System matches riders with drivers.
Notification Service updates both parties.
This is equivalent to identifying the core solution in a brute-force manner—it's functional but not yet efficient. The optimization comes later when we address scalability, fault tolerance, and other specifics.
Pro Tip: Treat high-level design as your "first draft" and focus on making it clear, concise, and functional. Avoid prematurely over-optimizing or diving into unnecessary details at this stage.
5. Deep-Dive Discussions
Why Are Deep-Dive Discussions Important?
Once the high-level design is complete, the next step is to anticipate potential challenges and refine the design to ensure it is robust, scalable, and efficient. Deep dives allow you to focus on key areas that are likely to cause issues or require advanced thinking.
Step 1: Identifying Potential Problems
The first step in deep-dive discussions is to analyze the high-level design and identify areas where challenges are likely to arise. Here are some common aspects to watch out for:
1. Scalability Bottlenecks
What to Look For:
Components or services that handle a large volume of requests.
Potential single points of failure or centralized resources.
Uneven distribution of load (e.g., hot partitions in a database).
Examples:
A ride-matching service might face a surge of requests during peak hours.
A leaderboard in a gaming app may see an imbalance in read vs. write operations.
2. Data Storage and Access Patterns
What to Look For:
Frequent read/write operations that might cause latency.
Large datasets requiring efficient storage and retrieval mechanisms.
Data consistency challenges, especially in distributed systems.
Examples:
Handling millions of location updates in a ride-hailing app.
Ensuring the accuracy of financial transactions in a payment system.
3. Fault Tolerance and Availability
What to Look For:
How the system behaves during partial failures or outages.
Dependencies on third-party services or external APIs.
Lack of redundancy or replication for critical components.
Examples:
What happens if the notification service goes down?
How to handle database node failures without impacting users?
4. Latency and Performance
What to Look For:
Components with strict latency requirements.
Operations that involve sequential processing or blocking.
Inefficient APIs or communication patterns.
Examples:
Location updates for ride tracking must be near real-time.
Search queries on large datasets can cause delays if not optimized.
5. Security and Privacy
What to Look For:
Sensitive data flows or storage areas.
Vulnerabilities to common attack vectors like SQL injection or DDoS attacks.
Compliance with data protection laws (e.g., GDPR).
Examples:
Encrypting payment information.
Protecting user data in a social networking app.
Step 2: Addressing the Problems with Common Solutions
Once you’ve identified potential problems, explore common strategies to address them. Here are some examples:
1. Solving Scalability Issues
Load Balancing: Distribute requests evenly across servers using techniques like round-robin or least connections.
Sharding: Split data across multiple databases or partitions based on keys (e.g., user ID).
Caching: Use in-memory stores like Redis to reduce the load on backend services.
2. Optimizing Data Storage and Access
Indexing: Use database indexing to speed up query execution.
NoSQL Databases: Choose NoSQL for unstructured data and high write throughput.
Read-Replicas: Create replicas of your database for read-heavy operations.
3. Ensuring Fault Tolerance
Redundancy: Add backup servers and databases to ensure service continuity.
Circuit Breakers: Implement circuit breakers to gracefully degrade service during failures.
Retry Logic: Introduce exponential backoff strategies for failed requests.
4. Improving Latency and Performance
Asynchronous Processing: Offload non-critical tasks to background jobs.
CDNs: Use Content Delivery Networks to serve static assets closer to users.
Database Optimization: Use query optimization and denormalization for performance gains.
5. Enhancing Security and Privacy
Encryption: Encrypt data in transit (TLS) and at rest (AES).
Authentication and Authorization: Use robust mechanisms like OAuth2 and role-based access control.
Rate Limiting: Throttle requests to prevent abuse or DDoS attacks.
Step 3: Identifying the Deep Dive Topics
After addressing the common challenges, prioritize deep-dive topics based on:
Criticality: Components that, if they fail, will severely impact the system (e.g., the database or authentication service).
Complexity: Areas requiring intricate decision-making or trade-offs (e.g., choosing between consistent or eventually consistent databases).
Interview Focus: Topics frequently discussed in interviews, such as load balancing, caching strategies, or database sharding.
Deep-Dive Discussions in Action
For example, in a ride-hailing app, a potential deep dive could focus on real-time ride matching:
Scalability: How to handle surges in ride requests.
Latency: Ensuring driver location updates are sent in milliseconds.
Fault Tolerance: Fallback mechanisms if the primary matching service fails.
Conclusion
Mastering system design is about breaking complexity into manageable steps. By systematically addressing requirements, entities, APIs, high-level design, and deep dives, you’ll be equipped to tackle any system design question confidently.
In the next blog, we’ll put this framework into practice by solving a real-world design problem from requirements to implementation!